Peking University, December 12, 2025: Recently, the College of Chemistry and Molecular Engineering, in collaboration with the School of Computer Science, and Yuanpei College, has introduced SUPERChem. This new benchmark targets a critical gap in evaluating LLMs: the lack of complex, multimodal, and process-oriented assessment in chemistry. SUPERChem introduces a systematic framework to rigorously evaluate LLMs’ chemical reasoning, advancing AI evaluation in scientific fields.
Background
While models like DeepSeek-R1 are shifting toward "Deep Thinking," existing science benchmarks remain focused on basic skills or are reaching saturation. Chemistry, which demands multi-step deduction and knowledge integration, is an ideal test bed for AI cognitive abilities. Leveraging the expertise of top-tier faculty and students, PKU designed SUPERChem to systematically evaluate deep chemical reasoning.

Figure 1. Overview of SUPERChem
Data Construction
Figure 2. The Three-Stage Review of SUPERChem.
The dataset was curated by nearly 100 doctoral candidates and senior undergraduates, including IChO and CChO medalists, through a three-stage review. It comprises 500 questions sourced from non-public examinations and science literature. 174 undergraduate students participated in establishing the human baseline.
A key innovation is Reasoning Path Fidelity (RPF), which compares the model’s chain-of-thought to expert-annotated reasoning steps, rather than only checking the final answer. This allows researchers to distinguish between genuine understanding and lucky guesses based on heuristics.
Evaluation Results
1. Frontier models approach second-year undergraduate levels, while reasoning consistency varies.
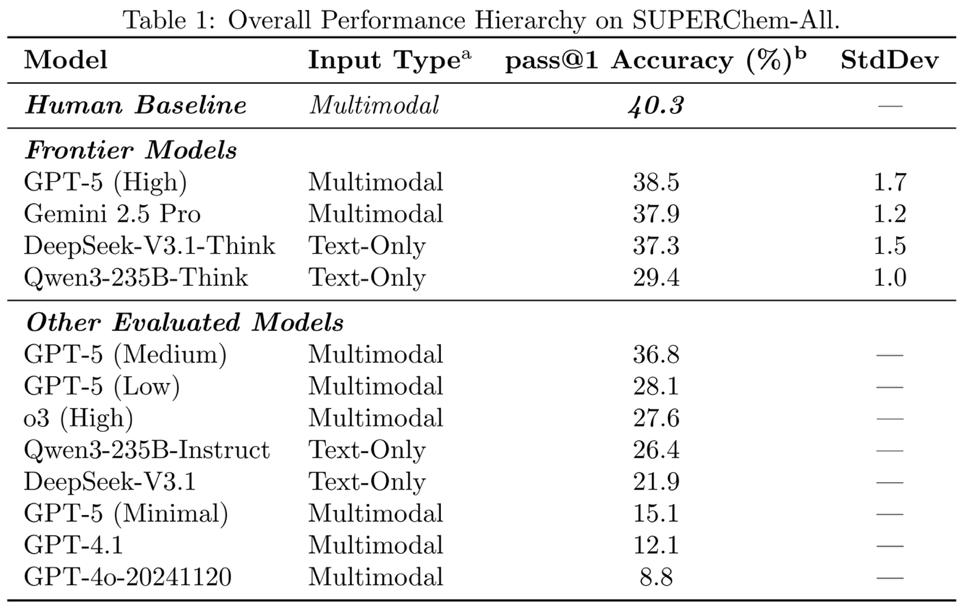
Table 1: Performance of Frontier Models.
In closed-book tests, the leading model, GPT-5 (High), achieved 38.5% accuracy, comparable to the 40.3% scored by second-year PKU chemistry majors. Tested models have not yet surpassed trained human expertise.
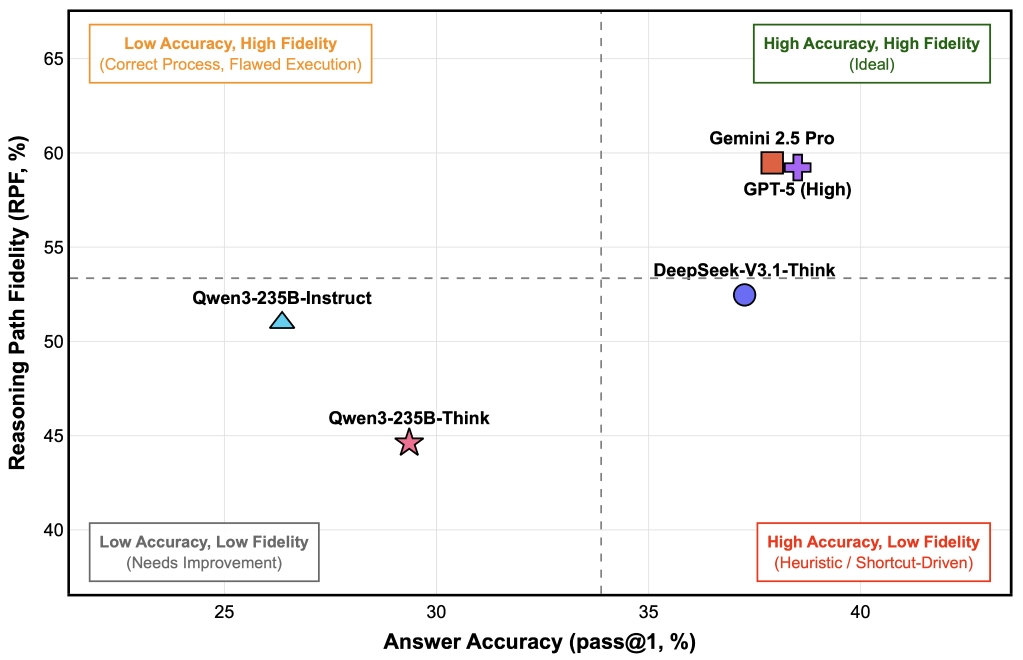
Figure 3. Relationship Between Accuracy and RPF in Frontier Models.
The RPF metric revealed significant differences in logic. While Gemini-2.5-Pro and GPT-5 (High) showed strong alignment with expert logic, models like DeepSeek-V3.1-Think scored lower on RPF despite similar accuracy, indicating a reliance on shortcuts.
2. The "Double-Edged Sword" of Multimodal Information.
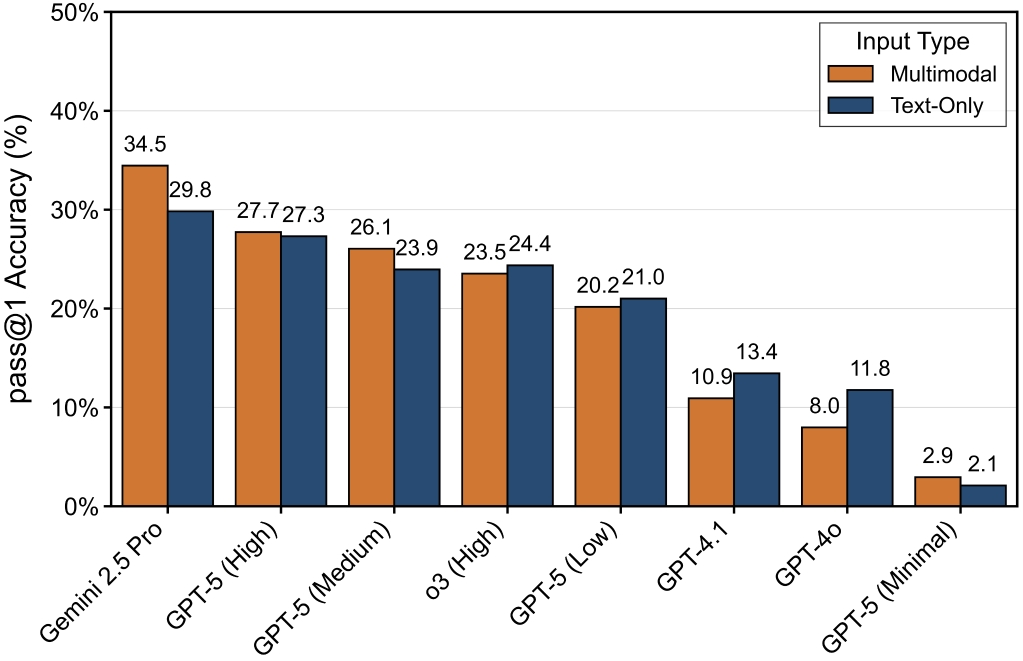
Figure 4: The Impact of Input Modality on Different Models.
Visual input boosts performance for strong reasoners but distracts models with weaker baselines (e.g., GPT-4o).
3. Analysis of Reasoning Breakpoints: Where do models fail?
Models struggle significantly with deep mechanistic tasks, such as predicting product structures and analyzing structure-activity relationships.
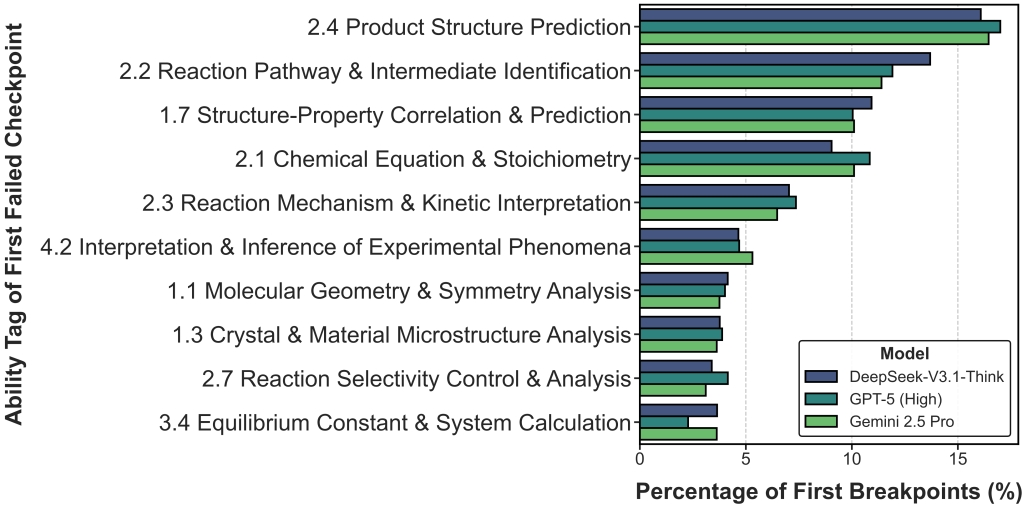
Figure 5. Distribution of Chemical Capabilities Associated with Reasoning Breakpoints.
Summary
SUPERChem proves that while today's frontier models possess foundational chemical knowledge, they still struggle with high-order reasoning. This benchmark offers a comprehensive framework to guide the future development of scientific AI.
Project resources
• Paper: https://arxiv.org/abs/2512.01274
• Dataset: https://huggingface.co/datasets/ZehuaZhao/SUPERChem
• Platform: https://superchem.pku.edu.cn
Edited by: Chen Shizhuo
Source: College of Chemistry and Molecular Engineering, Peking University









